Home - Teleport Blog - Microservices, Containers and Kubernetes in 10 minutes
Microservices, Containers and Kubernetes in 10 minutes
Last updated: December 2025
What is a microservice? Should you be using microservices? How are microservices related to containers and Kubernetes? If these things keep coming up in your day-to-day, and you need an overview in 10 minutes, this blog post is for you.
What is a Microservice?
Fundamentally, a microservice is just a computer program which runs on a server or a virtual computing instance and responds to network requests.
A microservice is not defined by how it is built but by how it fits into the broader system or solution.
What makes a service a microservice?
Generally, microservices have a more narrow scope and focus on doing smaller tasks well.
Let's explore further by looking at an example.
What is an example of a microservice?
Let's examine the system that serves you a product page on Amazon.
These pages typically contain several blocks of information, each likely retrieved from different databases:
- The product description, which includes the price, title, photo, etc.
- Recommended items, i.e. similar books other people have purchased.
- Sponsored listings that may be related to this item.
- Information about the author of the book.
- Customer reviews.
- Your own browsing history of other items on the Amazon store.
If you were to quickly write the code which serves this listing, the simple approach would look something like this:
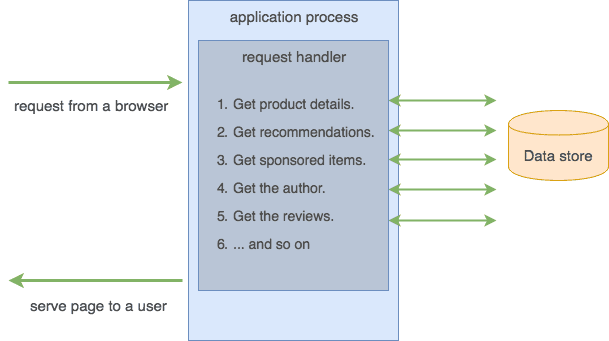
When a user's request comes from a browser, it will be served by a web application (a Linux or Windows process).
Usually, the application code fragment which gets invoked is called a request handler. The logic inside of the handler will sequentially make several calls to databases, fetch the required information needed to render a page and stitch it together and render a web page to be returned to the user.
What challenges do microservices solve in an application?
Many of Ruby on Rails books feature tutorials and examples that look like this. So, why complicate things, you may ask?
Imagine what happens as the application grows and more and more engineers become involved.
The recommendation engine alone in the example above is maintained by a small army of programmers and data scientists. There are dozens of different teams who are responsible for some component of rendering that page.
Each of those teams usually wants the freedom to:
- Change their database schema.
- Release their code to production quickly and often.
- Use development tools like programming languages or data stores of their choice.
- Make their own trade-offs between computing resources and developer productivity.
- Have a preference for maintenance/monitoring of their functionality.
As you can imagine, having these teams agree on everything in order to ship newer versions of the web store application will become more difficult over time.
How do microservices work in an application context?
The solution is to split up each of these components into smaller, separate services (aka, microservices).
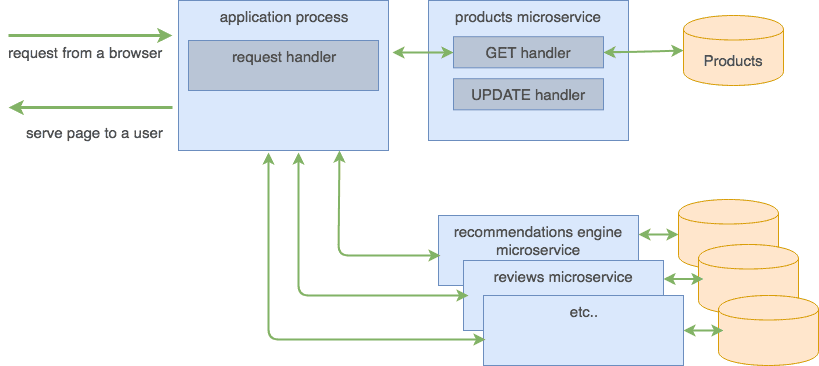
The application process becomes smaller and dumber, becoming what is essentially a proxy that breaks down the incoming page request into several specialized requests. These requests are then forwarded to the corresponding microservices, which are now their own processes and are running elsewhere.
The "application microservice" is basically an aggregator of the data returned by specialized services. You may even offload that job to the user's device by having this code run in a browser as a single-page JavaScript app.
The other microservices are now separated. Each development team working on their microservice can now:
- Deploy their service as frequently as they wish without disrupting other teams.
- Scale their service the way they see fit. For example, by using AWS instance types of their choice, or running on specialized hardware.
- Have their own monitoring, backups, and disaster recovery that are specific to their service.
How is this different from a typical Rails/Django/Node.js application?
It is not different at all.
In fact, you may discover that you already have dozens of microservices deployed at your organization. There are not any new magical technologies that qualify your application to be called a microservice.
What is a Container?
Technically speaking, a container is a process spawned from an executable file, running on a Linux machine, that has some restrictions applied to it. For example:
- A container is not allowed to "see" all of the filesystem, it can only access a designated part of it.
- A container is not allowed to use all of the CPU or RAM.
- A container is restricted in how it can use the network.
Historically, modern operating systems have always imposed restrictions on processes. Every Linux process runs with privileges of a system user, but containerization technology has introduced more possible restrictions and made them more flexible.
This means that any Linux executable can be restricted — or be "containerized".
When one says "container," they are not typically referring to just a Linux process. They are also referring to how the executable is packaged and stored.
Tools like Docker allow developers to take their executable and its dependencies (plus any other files they want) and package them all together into a single file. This technology is not too different from an archive like a tarball.
What is the difference between a container and a container image?
Docker also allows us to include additional instructions and configuration for running these packaged executables. Oftentimes these files, commonly known as "container images," are also called containers.
Container images are self-sufficient, and will run on any Linux machine. Containerization makes it much easier to copy (deploy) code from a developer's machine to another environment.
For the sake of simplicity, you can remember containers as such:
- A container is a Linux process with enforced restrictions
- A container image is a Linux executable packaged with its dependencies and configuration
What is the difference between microservices and containers?
We just learned that a container is just a method of packaging, deploying and running a Linux program/process. They are related, but do not require each other.
You could have one giant monolithic application as a container. Or, you could have a swarm of microservices that do not use containers at all.
A container is a useful resource allocation and sharing technology. It's something devops people get excited about.
A microservice is a software design pattern. It's something developers get excited about.
What are the benefits of microservices?
The benefits of microservices are numerous and include:
- Easier automated testing.
- Rapid and flexible deployment models.
- Higher overall resiliency.
Another win of adopting microservices is the ability to pick the best tool for the job. Some parts of your application might benefit from the speed of C++, while others would benefit from the increased productivity of higher level languages such as Python or JavaScript.
What are the drawbacks of microservices?
The drawbacks of microservices include:
- The need for more careful planning.
- Higher R&D investment up front.
- The temptation of over-engineering.
If an application and development team is small enough and the workload isn't challenging, there is usually no need to focus additional engineering resources into using microservices.
When should you use microservices?
However, if you are starting to see the benefits of microservices outweigh the drawbacks, here are some specific design considerations:
1. Separation of computing and storage
As your needs for CPU power and storage grow, these resources have very different scaling costs and characteristics. Not having to rely on local storage from the beginning will allow you to adapt to future workloads with relative ease.
This applies to both simple storage forms like file systems and more complex solutions such as databases.
2. Asynchronous processing
The traditional approach of gradually building applications by adding more and more subroutines or objects who call each other stops working as workloads grow and the application itself must be stretched across multiple machines or data centers.
Re-architecting an application around an event-driven model will be required. This means sending an event (and not waiting for a result) instead of calling a function and synchronously waiting for a result.
3. Embrace the message bus
This is a direct consequence of having to implement an asynchronous processing model. As your monolithic application gets broken into event handlers and event emitters, you will need a robust, performant, and flexible message bus.
There are numerous options, and your choice will ultimately depend on your application’s scale and complexity.
For a simple use case, something like Redis will do. If you need your application to be truly cloud-native and scale itself up and down, you may need the ability to process events from multiple event sources: streaming pipelines like Kafka, infrastructure, or monitoring events.
4. API versioning
Because your microservices will be using each other's APIs to communicate with each other via a bus, designing a schema for maintaining backward compatibility will be critical.
By simply deploying the latest version of one microservice, a developer should not be demanding everyone else to upgrade their code. This will be a step backward towards the monolith approach, albeit now separated across application domains. Development teams must agree upon a reasonable compromise between supporting old APIs forever and keeping the higher velocity of development. This also means that API design becomes an important skill. Frequent, breaking API changes is one of the reasons teams fail to be productive in developing complex microservices.
5. Rethink your security
Many developers do not realize this, but migrating to microservices creates an opportunity for a much better security model.
Because every microservice is a specialized process, it should have access to the resources it needs. This way, a vulnerability in one microservice will not expose the rest of your system to an attacker.
This is in contrast with a large monolith, which tends to run with elevated privileges (a superset of what everyone needs) creating limited opportunities to restrict the impact of a breach.
What does Kubernetes have to do with Microservices?
Kubernetes is too complex to describe in detail here, but it deserves an overview since many people bring it up in conversations about microservices.
Strictly speaking, the primary benefit of Kubernetes (aka, K8s) is to increase infrastructure utilization through the efficient sharing of computing resources across multiple processes.
What challenges does Kubernetes solve?
Kubernetes is the master of dynamically allocating computing resources to fill demand. This allows organizations to avoid paying for computing resources they are not using. However, there are additional benefits of K8s that make the transition to microservices much easier.
As you break down your monolithic application into separate, loosely-coupled microservices, your teams will gain more autonomy and freedom. However, they still have to closely cooperate when interacting with the infrastructure the microservices must run on.
You will now need to solve problems like:
- Predicting how much computing resources each service will need.
- How these requirements change under load.
- How to carve out infrastructure partitions and divide them between microservices.
- Enforce resource restrictions.
Kubernetes solves these problems quite elegantly and provides a common framework to describe, inspect and reason about infrastructure resource sharing and utilization. That's why adopting Kubernetes as part of your microservice re-architecture is a good idea.
How should you best use Kubernetes?
Kubernetes, however, is a complex technology to learn and it's even harder to manage.
You should take advantage of a hosted Kubernetes service provided by your cloud provider if you can. However, this is not always viable for companies who need to run their own Kubernetes clusters across multiple cloud providers and enterprise data centers.
For such use cases, you can test out Teleport Community Edition — or sign up for a free trial of Teleport Enterprise to access more advanced features.
TL;DR
- Containers are just Linux processes with applied restrictions. Examples of restrictions include how much CPU or memory a process is allowed to use. Tools like Docker allow developers to package their executables with dependencies and additional configuration. These packages are called container images and frequently and confusingly are also called containers.
- Microservices are not new. It's an old software design pattern which has been growing in popularity due to the growing scale of Internet companies. Microservices do not necessarily have to be containerized. Similarly, a monolithic application can be a microservice.
- Small projects should not shy from the monolithic design. It offers higher productivity for smaller teams.
- Kubernetes is a great platform for complex applications consisting of multiple microservices.
- Kubernetes is also a complex system and hard to run. Consider using hosted Kubernetes if you can.
Helpful resources
- Learn: What is a Kubernetes Cluster?
- Learn: What is RBAC?
- Blog: Kubernetes Namespace Restriction and Separation
- How-To: Kubernetes Access & Security How-To Guides
- How-To: Configure RBAC for Kubernetes EKS
- How-To: Authenticate AWS EKS Clusters with GitHub SSO
- How-To: Secure Access to Kubernetes Clusters
Table Of Contents
- What is a Microservice?
- How do microservices work in an application context?
- What is a Container?
- What is the difference between microservices and containers?
- What are the benefits of microservices?
- What are the drawbacks of microservices?
- When should you use microservices?
- What does Kubernetes have to do with Microservices?
- TL;DR
- Helpful resources
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.

Tags

Subscribe to our newsletter
