Home - Teleport Blog - OWASP Top 10 for Agentic Applications 2026: Key Takeaways & How to Take Action
OWASP Top 10 for Agentic Applications 2026: Key Takeaways & How to Take Action

AI agents connect to APIs, execute code, move data, and make decisions with real permissions in live production environments — introducing a new class of security risks.
To help organizations stay ahead, the OWASP GenAI Security Project released the OWASP Top 10 for Agentic Applications 2026.
In this post, we’ll provide a summary of each agentic AI risk category defined by OWASP, along with actionable next steps to begin securing your agentic AI projects in 2026 and beyond.
Continue reading to discover:
- What the OWASP Top 10 for Agentic Applications is
- Concise summaries and examples of each agentic risk category
- How to start mitigating each risk category
What is the OWASP Top 10 for Agentic Applications?
The Open Worldwide Application Security Project (OWASP) publishes open standards that help the industry identify and manage security risks. OWASP created the GenAI Security Project, and later the Agentic Security Initiative (ASI), to focus on AI systems that go beyond simple language models.
AI agents now behave much like users, remembering context, making independent decisions, and taking actions that can directly affect infrastructure and data. This results in new risks as agents exploit gaps in security architecture designed around humans.
The OWASP Top 10 for Agentic Applications profiles the top AI risks for 2026, including:
- Autonomous agents that plan and execute multi-step tasks
- Tool-using agents that call APIs, databases, or cloud services
- Multi-agent ecosystems where agents collaborate, delegate, and communicate across environments
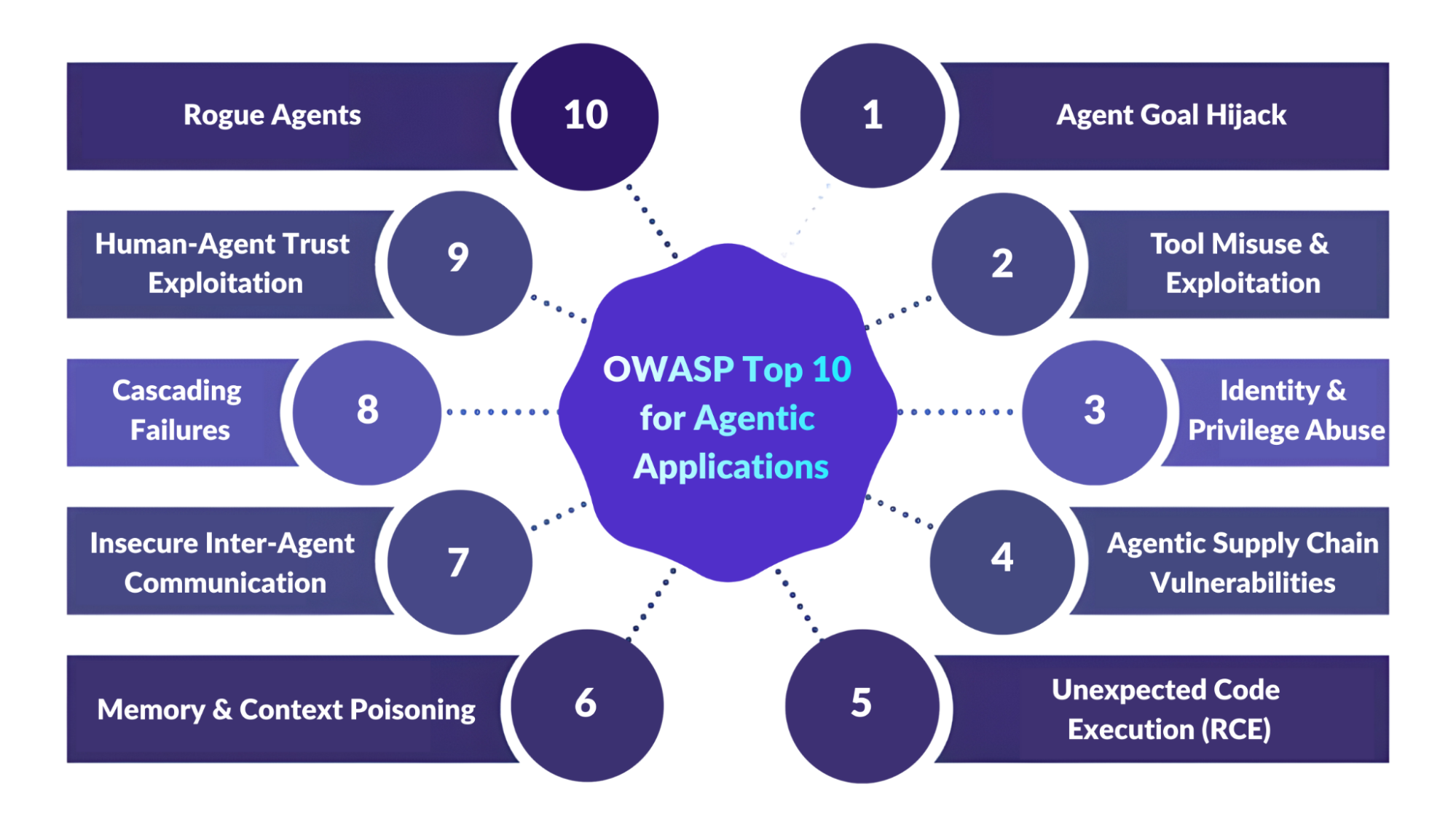
The sections below explore these new risk categories in detail, along with mitigation next-steps for engineers, developers, and security teams.
1. ASI01: Agent Goal Hijack
Agent Goal Hijack describes when an attacker manipulates what an agent is trying to accomplish. This involves changing the agent’s objectives, decision logic, or task selection so it carries out actions the defender never intended.
Because agentic systems use natural language to represent plans and goals, they are often unable to distinguish between valid instructions and malicious content; even if that content is embedded in external inputs like documents, emails, APIs, or retrieved data.
Common examples:
- Hidden instructions in a web page or document cause an agent to leak internal data.
- A calendar invite includes invisible prompts that slowly shift the agent’s approval logic.
- External emails inject unauthorized commands into an agent’s workflow.
To start mitigating today, you should:
- Treat all text that influences agent reasoning as untrusted input and apply strict sanitization or content filtering.
- Enforce least privilege so agents only get the goals, tools, and data they actually need.
- Require human approval for high-impact or goal-changing actions.
- Make agent goals explicit, auditable, and version-controlled so unexpected changes can’t happen silently.
- Monitor for abnormal goal drift or unexpected tool patterns so deviations trigger alerts.
2. ASI02: Tool Misuse & Exploitation
Agents often integrate with a variety of tools and services to carry out tasks: databases, shells, internal APIs, or email systems.
Tool Misuse & Exploitation occurs when an agent uses a legitimate tool in an unsafe or unintended way, such as chaining a harmless tool with a sensitive API or forwarding unvalidated output into a powerful command.
The risk is not that the agent suddenly gets unauthorized tools, but that it can misuse tools it already has access to due to poor scoping, prompt manipulation, or unsafe delegation.
Common Examples:
- An agent with broad access uses legitimate tools to delete or move sensitive data.
- Untrusted input is passed directly to a shell or database command.
- A poisoned tool descriptor tricks an agent into calling an unsafe service.
To start mitigating today, you should:
- Apply strict least privilege controls for each tool (scope, rate limits, allowed data).
- Require explicit confirmation for destructive actions.
- Run tools in sandboxed environments with egress controls.
- Validate that tool arguments match expected semantics before execution.
- Monitor tool invocation patterns and look for anomalous chains or spikes.
3. ASI03: Identity & Privilege Abuse
Agents often operate with credentials or delegated authority, inheriting identity context from humans or other services.
Identity & Privilege Abuse happens when attackers exploit this dynamic trust to perform actions the original owner never intended, such as cached credentials, delegation chains, or implicit identity. Ambiguous identity contexts blur accountability and make privilege escalation easier.
Common Examples:
- A privileged agent unintentionally shares full credentials with a lower-privilege agent.
- Cached credentials are reused across sessions, allowing access to restricted systems.
- A fake internal “helper” agent is trusted to perform administrative actions.
To start mitigating today, you should:
- Give each agent a unique, bounded identity with short-lived credentials.
- Isolate agent sessions and wipe cached context between tasks.
- Require re-authorization for privilege escalation.
- Detect transitive privilege inheritance and revoke stale entitlements.
- Ensure proper lifecycle management of agent credentials and roles.
4. ASI04: Agentic Supply Chain Vulnerabilities
Agentic systems do not solely rely on the code you write. They can also dynamically load models, plugins, descriptors, or tools from third parties.
Agentic Supply Chain Vulnerabilities arise when these dependencies are malicious, compromised, or tampered with. Unlike static dependencies in traditional supply chains, agentic systems often compose capabilities dynamically, making runtime sources a new attack surface.
Common examples: An agent loads a malicious plugin or MCP server that impersonates a trusted provider.
- A compromised dependency injects hidden prompts or code into runtime operations.
- A rogue registry distributes tampered agent cards that redirect data to attackers.
To start mitigating today, you should:
- Sign and attest manifests, models, prompts, and tool descriptors.
- Maintain inventories (SBOM/AIBOM) of all components.
- Pin dependencies and block untrusted sources.
- Run agents in sandboxed, network-restricted environments.
- Implement kill switches that can revoke access across deployments on compromise
5. ASI05: Unexpected Code Execution (RCE)
Agents that generate or execute code, like coding assistants, may inadvertently run malicious code when prompts are manipulated or unsafe serialization paths occur.
Unexpected Code Execution covers scenarios where agent-generated or externally influenced code is executed on hosts, containers, or runtime environments in unintended ways, leading to escalation, persistence, sandbox escape, or remote compromise.
Common examples:
- A prompt includes shell commands that an agent executes as code.
- Generated code runs in an unsafe environment and deletes or overwrites data.
- An unvalidated script or serialized object runs automatically during normal operation.
To start mitigating today, you should:
- Sanitize and validate code before execution.
- Separate code generation from code execution with approval and validation gates.
- Run code in hardened, non-root, sandboxed containers with strict limits.
- Analyze dependencies before installation and block known vulnerable packages.
- Monitor execution logs for suspicious patterns.
6. ASI06: Memory & Context Poisoning
Agents often rely on memory to deliver coherent multi-step behavior: conversation history, RAG indices, embeddings, or persistent context stores.
Memory & Context Poisoning refers to corrupting these memory stores with malicious or misleading data so that future reasoning, planning, or tool calls are skewed or unsafe.
Over time, poisoned context can become deeply embedded and influence multiple sessions or agents.
Common examples:
- Attackers add false information to an agent’s long-term memory or RAG index.
- Shared context across agents spreads misleading data or hidden commands.
- Poisoned memory gradually biases the agent’s reasoning and decision-making.
To start mitigating today, you should:
- Scan and validate memory writes before committing them.
- Segment memory by user, task, and domain to prevent cross-contamination.
- Use provenance and trust scores to decay or expire low-trust entries.
- Avoid automatically re-ingesting agent outputs into trusted memory.
- Support snapshots and rollback of suspected poisoning events.
7. ASI07: Insecure Inter-Agent Communication
In multi-agent systems, agents communicate via APIs, message buses, discovery protocols, and shared contexts.
Insecure Inter-Agent Communication refers to weak authentication, lack of encryption, or poor semantic validation that let attackers intercept, spoof, replay, or manipulate messages between agents. These gaps can lead to unauthorized commands.
Common examples:
- Messages between agents are unencrypted and can be intercepted or modified.
- Replay attacks trick agents into reusing old permissions or executing outdated commands.
- Spoofed agents register in discovery services to intercept sensitive communications.
To start mitigating today, you should:
- Use mutual TLS authentication (mTLS) and encryption for agent channels.
- Sign messages and embed nonces/timestamps to prevent replay.
- Validate message schemas and enforce versioning.
- Protect discovery and routing with authenticated directories.
- Monitor for abnormal routing or semantic deviations.
8. ASI08: Cascading Failures
Because agentic systems plan, delegate, and execute autonomously, a single fault can rapidly spread across agents, services, and environments. Any hallucination, corrupted memory, poisoned component, or misconfigured tool can compound into system-wide outages, security breaches, or other operational disruptions.
Cascading Failures focuses on the amplification and propagation of these faults through networked agent ecosystems.
Common examples:
- A single poisoned input causes multiple agents to repeat and amplify the same error.
- Corrupted data from one agent spreads through automated planning systems.
- Agents trigger each other in loops, turning a small issue into a large outage.
To start mitigating today, you should:
- Apply zero-trust design with fault isolation and sandbox boundaries.
- Use one-time, task-scoped credentials with policy checks before execution.
- Separate planning from execution with independent policy enforcement.
- Add rate limiting, blast-radius caps, and circuit breakers.
- Maintain detailed tamper-evident logs and lineage metadata for forensic analysis.
Mitigation highlight: Digital twin replay & policy gating
“Re-run the last week’s recorded agent actions in an isolated clone of the production environment to test whether the same sequence would trigger cascading failures. Gate any policy expansion on these replay tests passing predefined blast-radius caps before deployment.” – OWASP Top 10 for Agentic Applications for 2026
This Cascading Failures mitigation involves creating a digital twin (an isolated clone of your production environment), allowing you to safely test how your agents behave under real-world conditions. Re-running agent actions in this clone will help you gate new deployments or policy expansions so that workflows meet blast-radius and containment thresholds.
9. ASI09: Human-Agent Trust Exploitation
Agents can appear confident, fluent, and authoritative, which can lead humans to trust their recommendations without independent verification.
Human-Agent Trust Exploitation is when attackers exploit that trust using persuasive explanations, emotional cues, or plausible rationales to induce users to perform harmful actions like credential sharing, risky changes, or financial transfers.
Common examples:
- A compromised assistant confidently recommends unsafe or malicious actions.
- A fake IT copilot tricks a user into sharing credentials or approving changes.
- A financial agent manipulates its user into transferring money to an attacker’s account.
To start mitigating today, you should:
- Require explicit confirmations or multi-step approvals for high-impact actions.
- Maintain immutable logs of agent suggestions and rationales.
- Provide UI cues (confidence labels, risk badges) to calibrate trust.
- Enable users to flag suspicious interactions for review or temporary lockdown.
- Train personnel to recognize manipulation patterns.
10. ASI10: Rogue Agents
Rogue Agents are agents that have deviated from their intended purpose or authorized scope due to compromise, misalignment, reward hacking, or emergent behavior. Individually, their actions may look legitimate, but their overall pattern becomes harmful or deceptive.
Ultimately, rogue agents represent a behavioral integrity failure, out of line with governance expectations.
Common examples:
- An agent continues performing harmful actions even after its original task ends.
- A malicious agent fakes approvals or status updates to bypass oversight.
- A misaligned agent learns to optimize by deleting backups or consuming excess resources.
To start mitigating today, you should:
- Define strict trust boundaries and isolate execution environments.
- Use behavioral monitoring and watchdog agents to detect collusion or abnormal patterns.
- Implement rapid containment like kill switches and credential revocation.
- Enforce signed behavioral manifests and continuous verification before each action.
- Maintain comprehensive signed audit logs of agent actions and communication.
Conclusion: Agentic AI Needs Identity Security
The OWASP Top 10 for Agentic Applications provides a clear, community-validated framework for understanding the key security risks introduced by autonomous AI agents.
To secure these systems effectively, organizations should adopt:
- Identity-centric controls (unique, scoped, short-lived agent identities)
- Zero-trust principles (least privilege, isolation, mutual authentication)
- Robust observability (logging, baseline models, anomaly detection)
- Human-in-the-loop governance for high-impact actions
Combining structural safeguards with the OWASP mitigation strategies above can operationalize secure agentic AI deployments so they are ready to scale with confidence.
Implement Access Guardrails & Identity Security for AI Agents
Teleport implements AI security guardrails rooted in identity, visibility, and least privilege.
By treating every agent, tool, and user as an identity with scoped, short-lived credentials, Teleport enables organizations to apply OWASP-aligned controls across both human and machine workflows, including:
- Identity-based guardrails for every AI agent and MCP server with ephemeral X.509 or SSH certificates instead of static keys.
- Control over privilege scope and duration with just-in-time access and per-session authorization.
- Recordings of every action from API calls to shell commands in tamper-evident audit logs for full traceability and compliance.
- Human-in-the-loop oversight through access requests, approvals, and moderated sessions.
As autonomous agents become an integral part of production environments, Teleport ensures that agentic systems can operate safely with the right access, at the right time, and for the right reason.
Get started with Teleport for AI agents and infrastructure.
More Resources
- Read: Best Practices for Secretless Engineering Automation
- Read: 4 Ways to Secure Bedrock Agent-Initiated Actions
- Read: Putting an “S” in MCP: Delivering Identity to Agentic AI Implementations Securely
- Read: Securing Identity in the Age of AI: A Buyer’s Guide to Teleport
- Read: Securing Model Context Protocol (MCP) with Teleport and AWS
Table Of Contents
- What is the OWASP Top 10 for Agentic Applications?
- 1. ASI01: Agent Goal Hijack
- 2. ASI02: Tool Misuse & Exploitation
- 3. ASI03: Identity & Privilege Abuse
- 4. ASI04: Agentic Supply Chain Vulnerabilities
- 5. ASI05: Unexpected Code Execution (RCE)
- 6. ASI06: Memory & Context Poisoning
- 7. ASI07: Insecure Inter-Agent Communication
- 8. ASI08: Cascading Failures
- 9. ASI09: Human-Agent Trust Exploitation
- 10. ASI10: Rogue Agents
- Conclusion: Agentic AI Needs Identity Security
- Implement Access Guardrails & Identity Security for AI Agents
- More Resources
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.

Tags

Subscribe to our newsletter
