The design of Teleport’s Discovery Protocol
Introduction
This article will be exploring the challenges Teleport engineers faced when designing a discovery protocol for Teleport and how we learned to channel our inner Gordon Gekko to create a greedy solution. Teleport helps to empower engineers by enabling remote, secure access to their infrastructure while meeting compliance requirements, reducing operational overhead and complete visibility into access and behaviors.
A Naive Discovery Protocol
A discovery protocol is a system of instructions for gathering information required to find and communicate with available network resources. Imagine that you have a service that is hidden behind a firewall or a device that does not have a public IP address. How could you reach a resource that doesn’t allow public direct access? In order to access those firewall protected resources you can configure a supported feature of the SSH protocol called reverse SSH tunnels. When configured, this allows users to connect back to services that are not publicly accessible when using a proxy.
This is a simple solution that can be easily implemented when there is only one resource behind the firewall that you are trying to access. The path for data to travel is simple and there is only ever one resource location and identity that the agent needs to be aware of.
Simple Problem
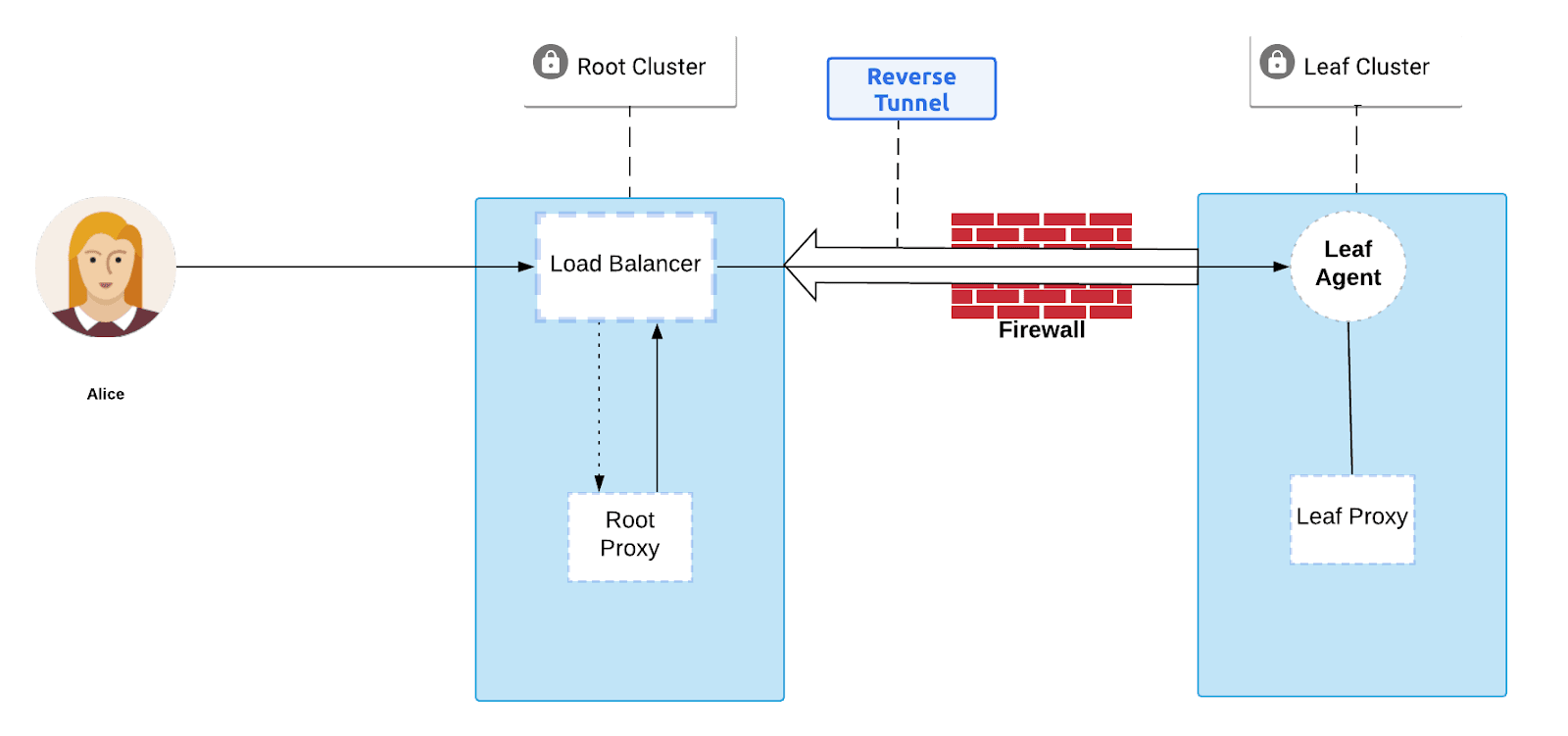
You can run into issues in a couple of places. One is if there is only one resource behind the firewall, but it may be in rotation and replaced with a new instance. Another arises if there are multiple resources to access. This added complexity can introduce the following breaking issues:
- How does the agent know that it has found and connected to all available proxies?
- Creates a complex data path for gossip messages to travel back to the leaf agent
- Gossip messages may arrive then be interpreted out of order by the agent
Problems with Multiple Proxies
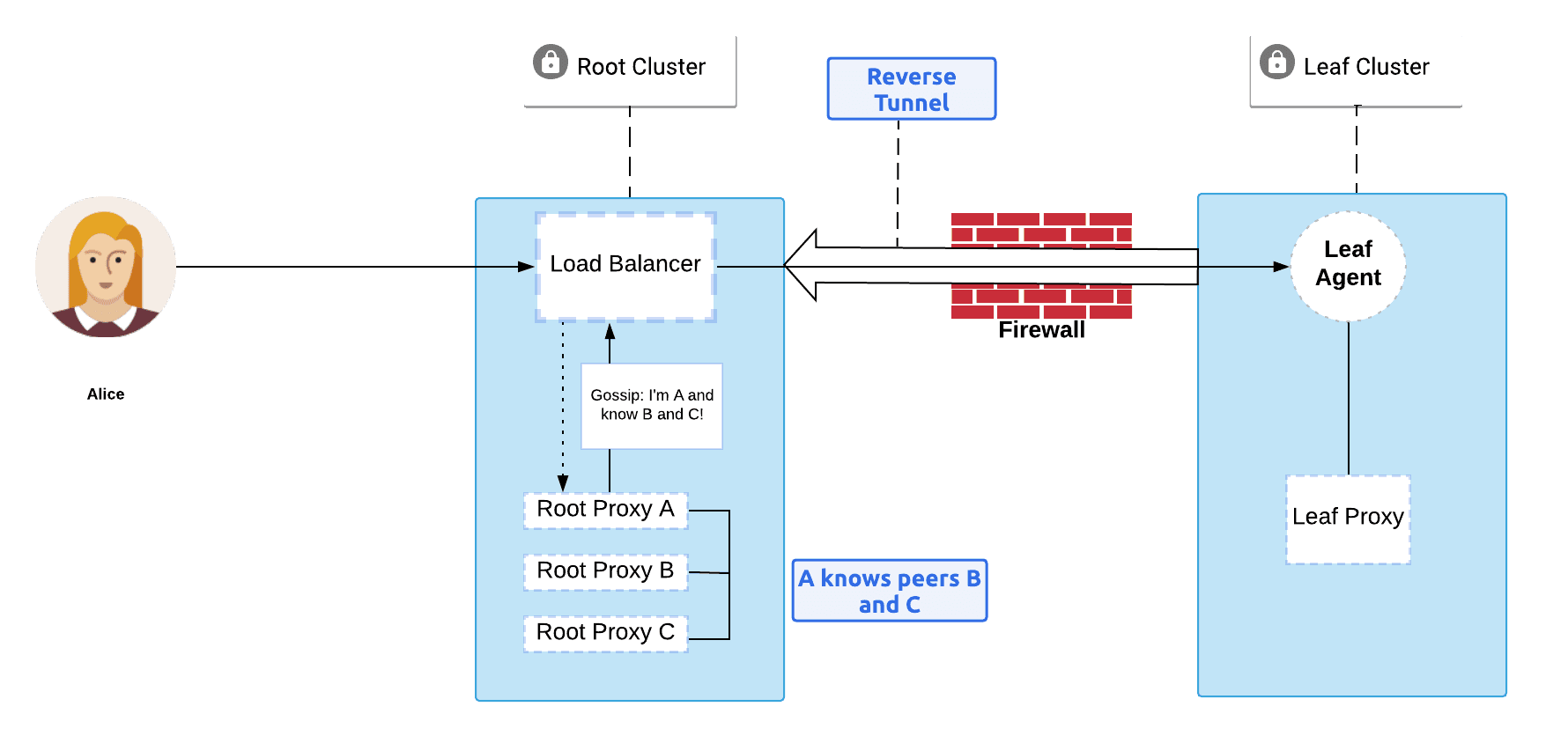
The basic steps of Teleport’s discovery protocol:
- The leaf proxy agent connects to Root Proxy Server A through the root cluster’s load balancer.
- Root Proxy Server A starts sending information about all available proxies to the leaf proxy agent. This process is called "sending discovery request". The leaf proxy agent will use the discovery request to establish new connections and check if it has connected or "discovered" all the proxies specified.
- When a leaf proxy agent discovers a root proxy server, it attempts to establish an exclusive claim. If successful, the leaf proxy agent takes responsibility for the root proxy server and releases its claim when the connection terminates. If another leaf proxy agent has already claimed the root proxy server, the connection is dropped.
- Once a connection is established the root proxy server sends a gossip message to the leaf proxy agent containing a list of its known peers (like Root Proxy B)
A reverse tunnel is created connecting a “leaf” cluster proxy to the “root” cluster proxy, which allows clients of the root cluster proxy to access servers of the leaf cluster even if the leaf cluster is behind the firewall.
The Trouble With Being Naive
Our early attempt to implement a discovery protocol encountered a number of issues:
- The leaf proxy agent did not know all the proxies available but was under the impression that it did
- The agent received proxy gossip messages out of order which resulted in a “stuck state” that the agent could not exit from
These issues were caused by:
- The assumption that the most recent gossip message received by the leaf proxy agent was the absolute truth of current reality
- The agent discarding any gossip messages that was seen prior to the last message received
Since proxy servers are rotated in and out of service, an out-of-order gossip message providing incorrect information could cause the agent to reach a “stuck state” and constantly search for proxies that no-longer existed. In this state the agent would ignore the proxies that did exist because from its perspective those were stale entries.
The below is a timetable of how the naive implementation was expected to work.
Ideally what would occur
| Timing | Proxy Agent Sees | Reality |
|---|---|---|
| 0 | (Noade A, Node B) | ( Node A, Node B) |
| 1 | (Noade A, Node B) | ( Node B, Node C) |
| 2 | (Noade B, Node C) | ( Node C, Node D) |
| 3 | (Noade C, Node D) | ( Node C, Node D) |
The below is a timetable of how a “stuck state” could be reached by rotating proxies out and messages arriving out of order.
What did occur
| Timing | Proxy Agent Sees | Reality |
|---|---|---|
| 0 | (Noade A, Node B) | ( Node A, Node B) |
| 1 | (Noade B, Node C) | ( Node B, Node C) |
| 2 | (Noade A, Node B) | ( Node C, Node D) |
| 3 | Stuck state reached! | ( Node C, Node D) |
Teleport Gets Greedy
The initial implementation of Teleport’s discovery protocol failed due to being heavily reliant on gossip messages being an accurate representation of reality and could not handle messages arriving out of order. An easy solution for this classic distributed data structure is to not bother with removing known proxies from the agent pool and don’t assume gossip messages are reliable (the latter might be good to apply in real life communications too). As such, our team turned towards creating a greedier discovery protocol.
The current implementation of Teleport’s discovery protocol operates under the assumption that received gossip messages might be accurate, but it does not accept this as the absolute truth and does not remove previously discovered proxies based on gossip messages.
Given that the load balancer is using a fair load balancing algorithm (such as the round robin protocol Teleport uses), the proxy agent will eventually discover and connect back to all the proxies. The proxy agent knows that it has discovered all proxy servers because every time it discovers and connects with a proxy, the proxy responds with a list of peers so agent can check it against its pool of known proxies to confirm that it knows everyone.
Teleport’s “greedy” implementation timeline
| Timing | Proxy Agent Pool Sees | Reality |
|---|---|---|
| 0 | (Noade A, Node B) | ( Node A, Node B) |
| 1 | (Noade A, Node B, Node C) | ( Node B, Node C) |
| 2 | (Node A, Noade B, Node C, Node D) | ( Node C, Node D) |
| 3 | (Node A, Noade B, Node C, Node D) | ( Node C, Node A) |
Teleport cybersecurity blog posts and tech news
Every other week we'll send a newsletter with the latest cybersecurity news and Teleport updates.
Conclusion
In this very specific scenario we align with Gordon Gekko’s assertion that greed is good and sometimes a more cynical approach to trusting information is necessary. If you would like to learn more about how Teleport simplifies privileged access management for Kubernetes and remote Linux servers you can check out our documentation and try out the open source version!
Important Terms
A Teleport proxy is a stateless service which performs three main functions:
- Serves as an authentication gateway
- Looks up IP address for requested nodes and then proxies a connection from client to node
- Serves a Web UI for cluster users to use
High availability (HA) is the ability of a system or system component to be continuously operational for a desirably long length of time.
SSH or Secure Shell protocol is a network protocol that secures communication between a client and a remote server.
Conflict-free replicated data type: In distributed computing, a conflict-free replicated data type (CRDT) is a data structure which can be replicated across multiple computers in a network, where the replicas can be updated independently and concurrently without coordination between the replicas, and where it is always mathematically possible to resolve inconsistencies which might result
Peer-to-peer gossip is a way to ensure that data is disseminated to all members of a group. Each node sends out some data to a set of other nodes. Data propagates through the system node by node like a virus. Eventually data propagates to every node in the system
A load balancer is a device that acts as a reverse proxy and distributes network or application traffic across a number of servers.
Round Robin load balancing is a simple way to distribute client requests across a group of servers. A client request is forwarded to each server in turn. The algorithm instructs the load balancer to go back to the top of the list and repeats again.
A node is a "server", "host" or "computer". Users can create shell sessions to access nodes remotely.
A cluster is a group of nodes that work together and can be considered a single system. Cluster nodes can create connections to each other, often over a private network. Cluster nodes often require TLS authentication to ensure that communication between nodes remains secure and comes from a trusted source.
Internet of Things (IoT) is a system of interrelated computing devices, mechanical and digital machines, objects, animals or people that are provided with unique identifiers (UIDs) and the ability to transfer data over a network without requiring human-to-human or human-to-computer interaction.
Table Of Contents
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.