The Pitfalls of Language Runtimes and Multi-tenant Services
Modern languages like Python, NodeJS, and Go make it easy to handle concurrent requests for multiple customers at the same time by using threads or goroutines.
Such services seem very cost effective because one process can handle hundreds or thousands of tenants. However, this efficiency comes at a hidden, steep price. When language runtime scheduling breaks down, one tenant can cause an outage for everyone.
Concurrency made simple
Go makes it trivial to handle concurrency.
Here is an example from A Tour Of Go that launches two goroutines that work independently of each other:
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
The Go runtime makes sure that each goroutine gets its fair share of CPU and memory. It gives the impression that both run in parallel:
# GOMAXPROCS sets system threads to 1
# This sets up the go language runtime to use one system thread across
# all goroutines. Removing this setting will introduce some parallelism,
# but will not solve the problems described in this article.
$ GOMAXPROCS=1 go run main.go
world
hello
hello
world
...
Language Runtimes and Multi-Tenancy
Let’s implement a sample Go SaaS that fetches the contents of a URL for multiple tenants in parallel:
package main
import (
"fmt"
"net/http"
"sync"
)
// fetch in our example performs some SaaS work for a tenant,
// in this case it gets the URL contents from the internet
func work(wg *sync.WaitGroup, tenant int, url string) {
defer wg.Done()
// Don't ignore errors in real code, folks, and close the response body
re, err := http.Get(url)
if err != nil {
fmt.Printf("Tenant(%v) error -> -> %v\n", tenant, err)
return
}
defer re.Body.Close()
fmt.Printf("Tenant(%v) -> %v\n", tenant, re.Status)
}
func main() {
// wg waits for a collection of goroutines to finish
// https://golang.org/pkg/sync/#WaitGroup
wg := sync.WaitGroup{}
url := "http://www.golang.org/"
for tenant := 0; tenant < 3; tenant++ {
wg.Add(1)
// 'go' starts a goroutine, a lightweight thread which is managed by the Go runtime
// https://tour.golang.org/concurrency/1
go work(&wg, tenant, url)
}
// wait for all goroutines to finish
wg.Wait()
}
My computer runs the program in no time:
$ go run simple/main.go
Tenant(2) -> 200 OK
Tenant(1) -> 200 OK
Tenant(0) -> 200 OK
We can imagine that the Go runtime executes the program in the following order:
goroutine0 = call work with args(0, "http://golang.org")
handle0 = http.Get("http://golang.org")
handles.Add(handle0, goroutine0)
sleepingGoroutines.Add(goroutine0)
goroutine0 = call work with args(1, "http://golang.org")
handle1 = http.Get("http://golang.org")
handles.Add(handle1, goroutine1)
sleepingGoroutines.Add(goroutine1)
...
// main program waits until any function returns data from the internet
handle = epoll(handles)
...
// Continue execution of goroutine 0
print(response)
// main program waits until any other handle returns data from the internet
handle = epoll(handles)
// Continue execution of goroutine 0
print(response)
This parallelism and blocking call is an illusion created by a combination of the use of the asynchronous
epoll Linux function
and Go's built in runtime scheduler. epoll can efficiently handle thousands of network sockets at once.
The Go runtime activates a smart scheduler to handle go statements - goroutines.
It makes sure that every goroutine gets its share of CPU time and suspends
execution when the function is waiting on network or file input/output.
It's not unusual to have tens of thousands of goroutines in the system
and see the Go runtime handle the requests well.
If you are interested in a more detailed intro to the Go scheduler, take a look at this article from Ardan Labs.
This makes Go a great language for handling concurrent network requests that constitute the bulk of an average software as a service program that reads and writes to a database or an external service.
When fair scheduling breaks down
Language runtimes do not have full control and visibility into the resource allocation that is done by the Linux kernel.
This is where the multi-tenancy service promise of fair scheduling breaks down.
Take a look at this number-crunching service that computes factorials on demand:
package main
import (
"fmt"
"sync"
"time"
)
// This implementation has a problem, but our code review did not catch it -
// all the engineers were busy arguing on HN.
func factorial(n int64) int64 {
b := int64(1)
for i := int64(1); i <= n; i++ {
b *= i
}
return b
}
func work(wg *sync.WaitGroup, tenant int, number int64) {
defer wg.Done()
number = factorial(number)
end := time.Now().UTC()
fmt.Printf("Tenant(%v) -> %v at %v\n", tenant, number, end.Format("15:04:05.000000"))
}
func main() {
// wg waits for a collection of goroutines to finish
// https://golang.org/pkg/sync/#WaitGroup
wg := sync.WaitGroup{}
for tenant := 0; tenant < 10; tenant++ {
wg.Add(1)
// 'go' starts a goroutine, a lightweight thread which is managed by the Go runtime
// https://tour.golang.org/concurrency/1
if tenant == 0 {
go work(&wg, tenant, 10000000000)
} else {
go work(&wg, tenant, 10+int64(tenant))
}
}
// wait for all goroutines to finish
wg.Wait()
}
In this case, you would not observe the same efficient parallelism.
My execution prints:
# GOMAXPROCS limits the execution to one CPU
$ GOMAXPROCS=1 go run fib/main.go
Tenant(9) -> 121645100408832000 at 00:20:42.111520
Tenant(1) -> 39916800 at 00:20:52.480150
Tenant(2) -> 479001600 at 00:20:52.480171
Tenant(3) -> 6227020800 at 00:20:52.480174
Tenant(4) -> 87178291200 at 00:20:52.480177
Tenant(5) -> 1307674368000 at 00:20:52.480179
Tenant(6) -> 20922789888000 at 00:20:52.480181
Tenant(7) -> 355687428096000 at 00:20:52.480184
Tenant(8) -> 6402373705728000 at 00:20:52.480209
Tenant(0) -> 0 at 00:20:52.480212
Because of the inefficient factorial implementation that took a lot of iterations and number crunching, tenant 0 consumed all the CPU time and degraded performance for the others.
We can fix the factorial function and add code that limits the possible input numbers. However, our service has just suffered an outage due to a bug in the code for all our customers, PagerDuty is ringing and we are not sleeping again.
A real-world example
I made up our factorial example, but let's create a real world one using decompression bombs.
Decompression bombs are specially crafted archives that are small, but expand into files ranging from tens to thousands of times their size.
They are specifically designed to take down your service. Anyone can download one from the internet.
Some archives use simple techniques like compressing very large files
filled with zeroes. They take advantage of the fact that compression algorithms
represent a huge file with zeroes with a version of repeat billion zeroes here.
More sophisticated approaches explore compression techniques in depth and craft evil files that can explode to petabytes of disk space. The danger is real and lots of programs are vulnerable on the internet right now.
Let's explore the effect of such archive on a multi-tenant service. Our new service unpacks the archive and counts the number of words in a file:
package main
import (
"bufio"
"bytes"
"compress/gzip"
"fmt"
"io"
"io/ioutil"
"log"
"sync"
"time"
)
func createArchive() []byte {
var buf bytes.Buffer
zw := gzip.NewWriter(&buf)
_, err := zw.Write([]byte("A long time ago in a galaxy far, far away..."))
if err != nil {
log.Fatal(err)
}
if err := zw.Close(); err != nil {
log.Fatal(err)
}
return buf.Bytes()
}
func count(wg *sync.WaitGroup, tenant int, archive []byte) {
defer wg.Done()
buf := bytes.NewBuffer(archive)
zr, err := gzip.NewReader(buf)
if err != nil {
log.Fatal(err)
}
unpacked := &bytes.Buffer{}
if _, err := io.Copy(unpacked, zr); err != nil {
log.Fatal(err)
}
if err := zr.Close(); err != nil {
log.Fatal(err)
}
words := 0
scanner := bufio.NewScanner(unpacked)
scanner.Split(bufio.ScanWords)
for scanner.Scan() {
words++
}
end := time.Now().UTC()
fmt.Printf("Tenant(%v) -> counted %v words at %v\n", tenant, words, end.Format("15:04:05.000000"))
}
func main() {
archive := createArchive()
// CAUTION: this can crash your computer.
// Take a gzip bomb from https://github.com/bones-codes/bombs
// https://github.com/bones-codes/bombs/raw/master/archives/10GB/10GB.gz.bz2
// bzip2 -d 10GB.gz.bz2 and then
bomb, err := ioutil.ReadFile("./10GB.gz")
if err != nil {
log.Fatal(err, bomb)
}
wg := sync.WaitGroup{}
for tenant := 0; tenant < 100; tenant++ {
wg.Add(1)
if tenant%2 == 0 {
go count(&wg, tenant, bomb)
} else {
go count(&wg, tenant, archive)
}
}
wg.Wait()
}
Here is a run on my machine:
$ go run multi.go
Tenant(1) -> counted 10 words at 01:32:57.558848
..
Tenant(63) -> counted 10 words at 01:32:57.888672
...
Tenant(21) -> counted 10 words at 01:32:58.337926
signal: killed
My computer terminated the process that ran out of memory.
Teleport cybersecurity blog posts and tech news
Every other week we'll send a newsletter with the latest cybersecurity news and Teleport updates.
Resource isolation with cgroups
The core of the problem is that CPU time is limited. Programming language runtimes lack the control and context required to efficiently distribute the CPU time per goroutine.
There is no great solution in the modern programming language runtime that solves this problem once and for all. Some language runtimes, like the Erlang preemptive scheduler provide more isolation and control. Unfortunately, Erlang does not solve the problem of memory management and its isolation comes with a performance cost.
There are some workarounds we can use today to provide better quality of service guarantees to our customers.
Engineers at Google recognized the problem of noisy neighbors in 2006 and introduced control groups.
Cgroups is a Linux kernel feature that limits, accounts for, and isolates the resource usage (CPU, memory, disk I/O, network, etc.) of a collection of processes.
Cgroups are exposed as a set of folders in Linux. It's easy to create a new control group.
$ mkdir /sys/fs/cgroup/cpu/cg1
Move a process to a cgroup by writing its PID into the cgroup cgroup.procs file:
# Place current process ID in control group cg1
$ echo $$ > /sys/fs/cgroup/cpu/cg1/cgroup.procs
# Reallocate CPU resources in this cgroup every 1 million microseconds (1 second)
$ echo 1000000 > /sys/fs/cgroup/cpu/cg1/cpu.cfs_period_us
# Let this cgroup have access to a single CPU for 0.2 seconds in a 1 second window
# roughly 20% of 1 CPU core
$ echo 200000 > /sys/fs/cgroup/cpu/cg1/cpu.cfs_quota_us
Start some number crunching:
# Thanks https://scoutapm.com/blog/restricting-process-cpu-usage-using-nice-cpulimit-and-cgroups for the demo tip
$ matho-primes 0 9999999999
Linux limits the process ambitions to 20% of the CPU pretty accurately:

We don't need to restart the process to raise the limit to 40% CPU. Writing a new value to the file works:
$ echo 400000 > /sys/fs/cgroup/cpu/cg1/cpu.cfs_quota_us
The system has adjusted and in a second, the program is crunching primes using 40% of the CPU:
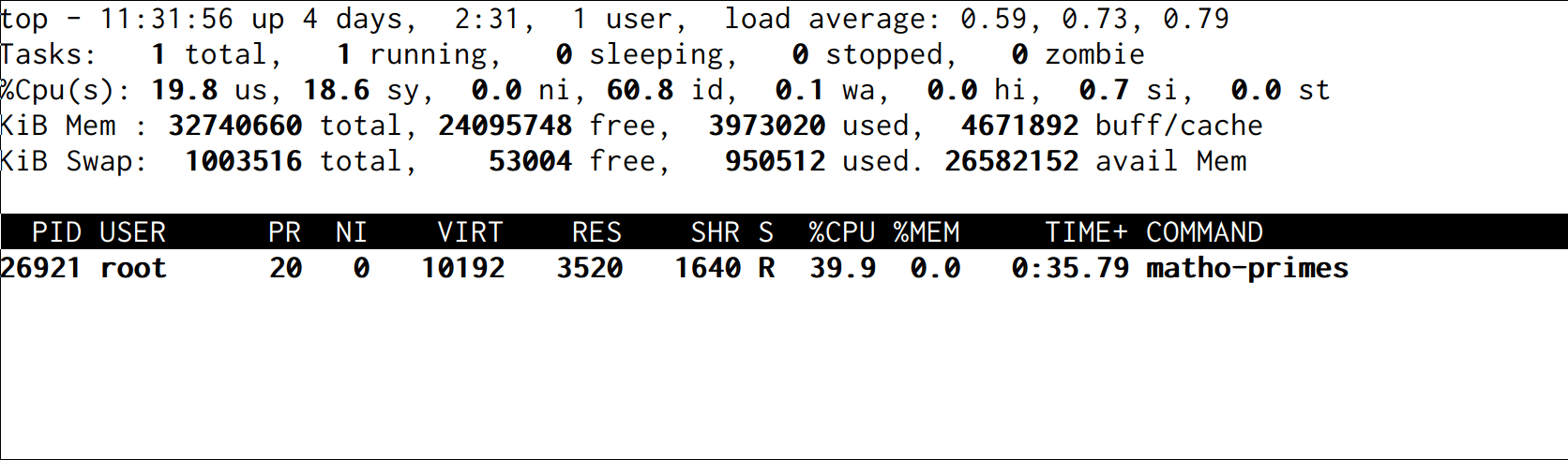
Orchestration platforms like Kubernetes make it easier to run multiple processes and set CPU and other resource constraints.
We will have to watch the latest developments in the kernel and programming language spaces that will solve this problem more efficiently in the future.
Until then, every tenant has to run as a separate process with cgroup limits.
If you’re interested in trying a fully hosted Teleport, you can sign up here.
Table Of Contents
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.
Tags
Tags
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.