The Horrors of Upgrading Etcd Beneath Kubernetes
Table Of Contents
- Introduction
- Who is Kevin and What is Etcd?
- Why Do Consensus Algorithms Matter?
- Why are Autonomous Upgrades of Etcd So Important?
- Finding an Upgrade Path That Allows Downgrades
- Using Full Backups and Restores Beneath Kubernetes
- Dealing with Etcd’s In-Place Upgrade Catch-22
- Using an External Coordinator While Etcd is Down
- Community Projects and How They Handle Etcd Upgrades
- The Horrors of the Backup and Restore Method
- Teleport cybersecurity blog posts and tech news
- Future Challenges Around Etcd & K8s Maintenance
Introduction
Proud new Kubernetes cluster owners are often lulled into a false sense of operational confidence by the consensus database’s glorious simplicity. And while etcd’s operability is rock-solid when fed sufficient disk IO, upgrading etcd in-place underneath fully-loaded Kubernetes YAMLs is still a dicey affair.

In this article we continue to decrease productivity at Teleport by prying an engineer from their flakey MacBook keyboard to discuss the toils of making complex software run by itself. In a previous interview, our CTO, Sasha Klizhentas, spoke to experiences running PostgreSQL on Kubernetes. Today, Kevin Nisbet digs into the horrors of in-place etcd upgrades and rollbacks within autonomous and inaccessible air-gapped clusters.
Who is Kevin and What is Etcd?
Abe: Kevin, thanks for taking the time to chat. Before we pick apart this nightmare, tell us who you are?
Kevin: Sure. I work on our platform that is optimized for running a lot of Kubernetes deployments, particularly Kubernetes deployments that you may not have your hands on, because they’re running within a customer’s data center, or any inaccessible environment. My background is in distributed systems and telecommunications.
Abe: Had you gone deep with etcd or similar consensus systems like Zookeeper before you had to automate etcd upgrades underneath Kubernetes?
Kevin: Yes. I used a different Raft implementation in a previous role as the underpinning for our security architecture, where we wanted an isolated key management system. I went deep into using that implementation and etcd is very similar.
Abe: For someone whose orientation is pre-Kubernetes, who has only operated things like active/passive load balancers, can you give a brief synopsis of Raft and Paxos-style consensus algorithms?
Kevin: Raft is a consensus algorithm for having a single, consistent, shared state on many, separate computers. Unlike the older incumbent algorithm for consensus, Paxos, which is very complicated to teach and implement, Raft was designed to be simple. It’s highly fault-tolerant and has an approachable academic paper on how it performs leader elections and achieves consensus among multiple machines in a reliable way. The basic principle is based off of having a single leader and a write log that feeds a state machine. First, you use an election process to determine a leader for the cluster. Then you write a log in a specific order—coordinated through the leader. Once the majority of your systems agree on a new entry in the log, then the change is considered committed and you get a response back. So, you’re able to have all of your systems agree on what’s logged without needing special clustering hardware.
Abe: A distributed state machine?
Kevin: That’s where things get really interesting. Now that each system has a coordinated, ordered series of events, they can be played through a state machine which is the application itself, in the case of etcd this is the implementation of the key value store. You can take snapshots of your state machine as a result of that log. When a new process starts from scratch, you don't have to replay the log from 100 days ago, or four years ago, you can replay it from your last snapshot, plus what's happened since then. Raft creates a lot of flexibility and it's also very approachable. It’s this simple and well defined consensus algorithm that helps us all write better distributed systems. There's a lot more to it, if you want to dive deeper I recommend you read this review by Kyle Kingsbury (aka, Aphyr) and the etcd repo.
Why Do Consensus Algorithms Matter?
Abe: What's the general applicability of consensus algorithms, what’s the big deal? Beyond Kubernetes or Docker Swarm hype, what does it mean to have open source Raft implementations that are lightweight & fast?
Kevin: Well, it gets you past this old single-node database mantra, which isn't really particularly old or even a wrong way to go. Raft gives you a new generation of systems where, if you have any type of hardware problem, any type of software instability problem, memory leaks, crashes, etc., another node is ready to take over that workload because you are reliably replicating your entire state to multiple servers.
Abe: Before we get into the horrors, what's your general take on etcd as a piece of software, as an engineering effort born by engineers at CoreOS long before RedHat’s acquisition?
Kevin: I think etcd is a great piece of software. It took on what has become this popular set of modern values, an easy to run static binary that you can run almost anywhere to get started. If you want to form a multi-node cluster, you pass it a little bit of configuration and off you go. So, for systems engineers and operations teams, etcd is really solid and easy to get going. You don't need a package maintainer that has done a whole bunch of magic work to make it run on your system, to coordinate all the data directories and distinct components. You can run in a container very easily. You can use your typical Ansible, Salt, or Puppet workflows to deploy it to hundreds of servers with ease.
Abe: Anytime ease is mentioned in relation to complex distributed systems, I start to wonder what’s really going on. What are these horrors you speak of?
Kevin: I want to be careful not to criticize etcd itself. We are in somewhat of a unique position in that we are delivering fully autonomous upgrades of etcd to our Gravity users. We were also doing multi-version migrations. Although, even if we forced more frequent and proactive incremental upgrades, we would still face a lot of the same challenges.
Why are Autonomous Upgrades of Etcd So Important?
Abe: For people who have heard of things like Bootkube, or dealt with kafkaesque edge cases of using “self-hosted” Kubernetes to upgrade Kubernetes itself, can you explain why we don’t do that? Why do we take a conservative approach?
Kevin: Well, the thing we do really well, compared to other products, is that we have an intense focus on upgrades—especially in hiding Kubernetes and the details of its underpinnings. Our customers can take all of their software, including all of this “cloud native” open source machinery, ship it to an air-gapped location without Internet egress, and someone who doesn't know anything about how the technology works can unzip a tarball, run ./upgrade, and, a few cups of tea later, the entire solution has been upgraded to a new release. You don't even need to know if Kubernetes is there. It's just a substrate that makes other software work well.
Abe: So things like GovCloud or a phone closet in Chick-fil-a?
Kevin: Exactly. Within that scope, there are many things that we do to make it easier for people to operate their clusters without internet access. This is why autonomous upgrades are critical, we can’t just swap out entire clusters for new ones.
Abe: One way I describe our on-premises SaaS platform is that it runs underneath Kubernetes as a machine that makes a cluster exist, and then reconciles everything required for a complex customer app on top of that. Is that a fair description from your point of view?
Kevin: I think you described it well. Our platform, for the purposes of applications, is basically Kubernetes. Kubernetes at its core is just cluster API machinery on top of etcd’s distributed state store. We deploy etcd in order to be a platform for Kubernetes and of course we also store our own platform’s information inside that same etcd component.
Kevin: So, software stack-wise, our platform has everything you need for Kubernetes, plus our management, security bastion and other layers that are required to operate tons of autonomous clusters successfully. We're connecting those pieces together and providing support for the whole stack. We’re on the hook if these clusters can not be successfully upgraded.
Finding an Upgrade Path That Allows Downgrades

Abe: When I peek at etcd’s upgrade documentation, it looks straightforward. Etcd has protocol-level backward compatibility. You start up a new binary that can still speak to the old versions, then you roll through this process, node by node, and don't lose consensus through the entire thing. The process of getting from the one release to the next, as described in that procedure, doesn’t look too bad. Is that actually true?
Kevin: It is. However, a stepped model makes it harder to support rollbacks. Rolling upgrades are fine if you’re stepping through the process for a single minor version and a human is available if any step doesn’t work perfectly. In our case, we needed to leap from version 2 to version 3.0; then, we leapt to version 3.1. We would have had to ship every incremental version to upgrade an old cluster. We're not an operator sitting in front of the system, we have to automate each step so that upgrades happen in the background without intervention.
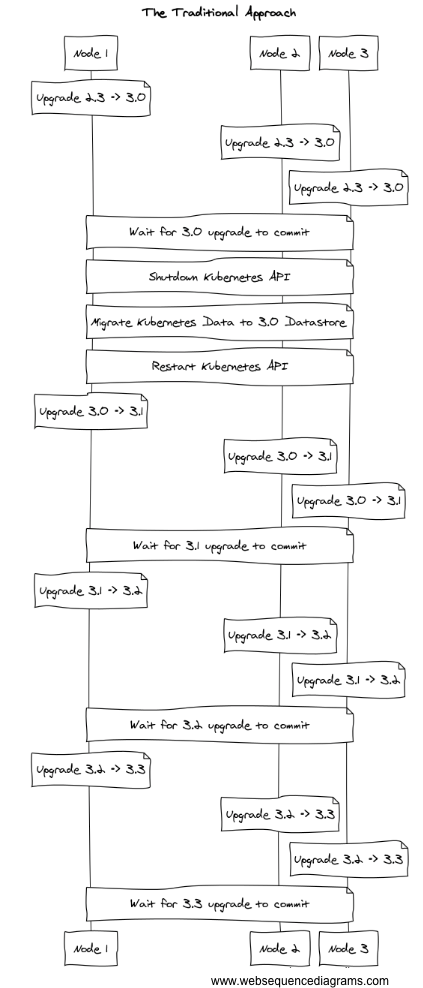
Abe: That's scary that there's no clean rollback procedure.
Kevin: Yeah. I don't remember what the docs say about rollback. I think upstream provides some tooling that lets you clone the data directory, the log and snapshots. I'm pretty sure you can't do it as a rolling rollback, or maybe you can but it didn’t feel like a well-supported path. And, you might have to shut down your entire cluster, restore all of the data directories from backup, restart them, and effectively do a full reset procedure if you go that model.
Abe: The process itself is changing the structure of data on disk such that the prior versions of etcd won't be able to understand the cluster state? If you muck up the rolling upgrade procedure, it's a stop-the-world hard restore from backup?
Kevin: That appears to be the case. The other thing, though, is, in our unique use case, you might not be rolling back because you mucked up the etcd upgrade. Our upgrade upgrades our entire platform, including dependencies like Docker. It even upgrades our customer’s baked-in software. If anything in that process doesn't work, you'll be rolling back to a previous release—which requires that etcd roll back with it.
Abe: I feel like I'm walking into one of those Halloween horror houses, and things are just going to start jumping out at me.
Kevin: Exactly, right? This is the thing. Etcd is good, simple software. But it's good, simple software when you're a cloud native company and you block out a period of time to do your etcd upgrades and nothing else. You have your maintenance window, you upgrade etcd, everything looks fine, you're good. If something goes wrong with just that tiny piece, you follow the roll back procedure, and everything is happy. But, with bootkube, with kops, and even with Gravity, you now have etcd as this magical, background component that something external is now upgrading and managing—hiding those things that a human operator would've traditionally done.
Using Full Backups and Restores Beneath Kubernetes
Abe: Once in a blue moon, you hear of a news story around Halloween where the masked chainsaw-wielding actor accidentally slices open a flailing limb in one of these horror houses. Because I'm talking to you, I’ll presume you made it out of the other side unscathed. What were the things that jumped out at you? What scared you the most? Did you just run through the dark holding your hands out in front of you? This notion is making me extremely nervous.
Kevin: Hah. We just spent a bunch of time breaking it down, trying to look at what other people are doing. The first solution we considered was actually a full Kubernetes backup and restore, at solutions like Ark. It uses the Kubernetes API to just download a copy of all your objects. If you go with a Kubernetes backup and restore model, you can actually just destroy your entire etcd cluster, start up a new one, and restore to it within the new version. If you want to roll back, it's actually the same process. You just destroy your newly updated cluster, start up a cluster on the old version, and restore to it. When your upgrade and rollbacks look like the same process, it tends to make them work a little bit more reliably.
Kevin: The reason we didn't end up on that model, or specifically Ark, was, within the Kubernetes API, there are some fields that you can’t really set. So, there's some risk that you’ll lose things, like your Amazon integration ELBs, which might need to be destroyed and recreated. And, we don't want any unintended side effects from upstream Kubernetes implementation or from bugs.
Kevin: So, we ended up using the same model, but stepped down a layer. We wrote a client that goes into etcd, copies everything in the etcd data store out to a format on disk, and then we don't destroy the old cluster. When we start up the new etcd version, we redirect all of its data directories to some new location on disk, start it up blank (as if nothing in the world exists), then write all of the keys and values back in. We're up and running. This isn't a perfect, highly available process because we do have to take etcd down for 30 seconds or a minute, but Kubernetes kubelets and clients will just see this as, "Hey, the apiserver's down for a minute. I'll just keep doing what I'm doing until it comes back."
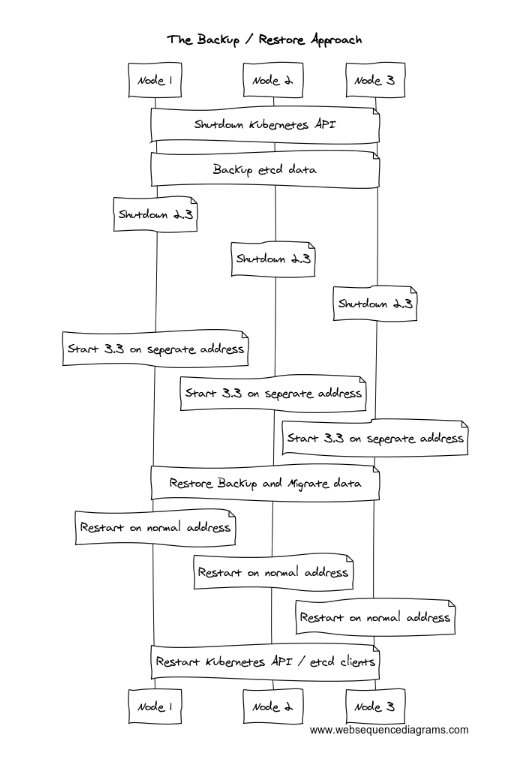
Abe: Fascinating. It's not a perfectly online upgrade; but, because you step down, you have the ability to rollback and the outage of the underlying data store should be quick enough that most applications wouldn't notice?
Kevin: Exactly. Most applications themselves don't directly use etcd. What you lose is: anything that's trying to write to, or make changes to, the Kubernetes cluster, won't be able to. But, for most of our deployments, we don't have kind of continuous writes or dynamic changes to Kubernetes objects.
Abe: I wonder about custom resource definitions, Kubernetes network security add-ons like Cilium or Calico that could have a high rate of change. What edge cases, where this approach wouldn't work, come to mind?
Kevin: I think you hit it. If, for whatever reason, the software can't tolerate a short outage to the Kubernetes API, or underlying software that does talk directly to etcd can't tolerate an outage, this will be tricky. However, realistically, you should be able to tolerate short outages on these systems anyways. Because, with etcd, if you're running a decently sized database and the leader has problems such as drive failures that takes it offline, it’s going to take some amount of time to re-elect. The re-election won't be as long as an upgrade, of course, but a glitch will occur.
Kevin: We've found that some of our big customers scale down their software while the platform is being upgraded. If you're using a scaled-down model, you’re reducing your control plane workload, you have spare resources to ease platform changes and should be less affected.
Abe: So, new cluster operators, or teams who have paranoid Prometheus alertmanager rules that pop off on ephemeral, non-critical, issues, they will notice minor blips caused by this kind of stepped upgrade procedure. Your typical cloud native application or stateful workload on top of Kubernetes shouldn't notice?
Kevin: Yeah, exactly. It really depends on the way you integrate things and the way that you react to failure. Most software I encounter—even software running as highly available and always on—will tolerate short glitches in an API on a service. When you're doing stuff like blue-green deployments, not every soft switch-over is perfect. In the routing layers in the carrier networking world, OSPF or BGP still take multiple seconds to converge, in many use cases.
Dealing with Etcd’s In-Place Upgrade Catch-22
Abe: These etcd upgrades are not happening in a vacuum where it's just etcd. Just like other operators who have layered stacks of software, other components of our platform have to be upgraded during the same window? That’s part of the nightmare here, too?
Kevin: Right, there are many, many moving parts in our overall upgrade process that happens in an ordered, consistent way across a fleet of servers. We don’t expose etcd to our customers at all. They can use it indirectly through the Kubernetes API, through custom resource definitions, or through config maps. We have difficulties when our coordination mechanism for our upgrade process is etcd. So, when we take etcd offline for a minute to do an upgrade across multiple masters, we're actually in a catch-22 where our state, for our upgrade, is in the etcd cluster that we just took offline.
Abe: I just walked into the horror house room where the strobe is going off.
Kevin: Exactly. That is the horror. It’s doing consistent coordination while you've taken the consistent datastore offline.
Abe: But, you still have etcd v2 or the old version running and can use that? How do you deal with this?
Kevin: No, we take the v2 cluster and shut it down completely. We don't want anything to continue to write to it and make changes after we've backed it up because then, when we restore, the new version would have part of its state missing.
Abe: So you’ve told the cluster to hang on and are walking through the dark with your hands outstretched hoping to find the wall on the other side of the room?
Kevin: Yes. The slight difference is we've extinguished the entire database. It's gone. And now, we're using something outside of etcd to keep state and continue the coordination as we execute each step of our upgrade process.
Using an External Coordinator While Etcd is Down
Abe: What's this thing that's outside of etcd?
Kevin: So, when we do automatic upgrades, we have one process that we launch, as a sort of coordinator, that uses an RPC mechanism to invoke steps on the rest of the cluster. That thing goes through everything you want to do as sequential steps—one, two, three, and so on. As part of dealing with these horrors, we re-designed the upgrade process to keep a stepped upgrade plan in a consistent local boltdb database. It's like SQLite for Go, but using a key-value store instead of SQL. This coordinator is writing to that node and to each node in the cluster. It keeps a consistent state. Every time it completes a step, it keeps a local copy now, as well.
Kevin: When etcd disappears, it's not really concerned. It will just continue telling all of the other nodes in the cluster to do their next step in the upgrade plan. When etcd comes back, it's happy. If something fails midway through, it can be a little bit tricky because now, depending on where you look for the state of truth on the upgrade, you might get a different view; which, are these intricate pros and cons we need to balance. That part is probably one of those things that we'll invest in further as time goes on. We’ll probably launch a separate, standalone etcd consensus store just for the upgrade process. That was deemed too complex for now.
Abe: If something funny happens, when you're coordinating by way of RPC across individual nodes, a network partition, or one of the nodes failing, is it just a fatal error? Is it Pagerduty time, an escalated support ticket? Or, does the stepped coordinator code deal with that?
Kevin: Current implementation is it's just going to stop, and yeah, it's Pagerduty time.
Community Projects and How They Handle Etcd Upgrades

Abe: Did you actually go and look at prior implementations from other projects as you were digging into this stuff?
Kevin: Yeah, I spent a good deal of time doing so. And, even since then. Because, the part to keep in mind is, we're probably developing this in parallel with a bunch of other people who have live clusters and who will also be forced to gracefully upgrade to etcd. There are many clusters that are already deployed and have this problem. They each need to find their own way for their use cases.
Kevin: Inside of the main kubernetes repository, there’s a container-based etcd, that I'm not sure if it's used by kubeadm or something else, which implemented this model of, "Okay, detect if the cluster is on v2. Then, upgrade it to v3. And, now wait for the internal stuff where etcd does its protocol upgrade. And, when the entire cluster's upgraded, then upgrade it to 3.1, and then to 3.2." This is a background process that would be kicked off and hidden to an outside observer. If it works every time, that’s perfect. The difficulty with adopting something like that, again, is in the case of a rollback. Adopting that upstream path won’t fly with the way that we've chosen to deploy our software, where we rollback everything..
Kevin: The other thing is, when I looked at it, it appeared to be incomplete. It could do this on a single node, but I think the multi-node stuff was a to-do item. They have the same problem we do. Ideally, you'd have a coordination mechanism outside of etcd to tell all the nodes, "Okay, we're happy. We can continue rolling to the next version."
Kevin: I also spent some time looking through what CoreOS was recommending. Details within their notes highlighted another API glitch that we haven't discussed yet: going from etcd2 to etcd3 using migrations. Because etcd3 is a different API, it has a different storage backend than etcd2. So, even if you do the recommended upgrade path from etcd2 to etcd3, you can't access any of the data that you upgraded through the etcd3 API. Etcd runs both API versions smashed together. The etcdctl command line does provide tools for migrating data from etcd2 API to the etcd3 API. But, when I looked, the upstream upgrade documentation recommends that you do it as an offline process.
Abe: I feel like I’m in a hall of mirrors, where each is a GitHub issue that leads to a dozen other open GitHub issues.
The Horrors of the Backup and Restore Method
Kevin: Welcome to my life. One of the other horrors is the way etcd clients monitor for writes. Etcd will tell listeners that, “Hey this object changed.” And, one of the fields in there is the Raft index. That pointer will change from our backup and restore so that if there’s a listener that’s not expecting etcd to disappear, it’ll get freaked out when it suddenly reappears with a totally different ID. We can control our own software to make sure it handles this or we can restart any software that doesn't.
Abe: The Raft index is like a private, primary key in a database? Where if you do a full sql dump and sql reload, the primary keys may change?
Kevin: Exactly. The tricky bit that might come back to bite us at some point is that Kubernetes exposes this behavior when you're monitoring the Kubernetes API for object changes. Their documentation currently states, "Don't assume a specific behavior." That’s what we're relying on. The clients of Kubernetes aren't expecting it to always expose an etcd-like behavior—where IDs can only move forward and will never move backward.
Abe:: Is it a leaky abstraction on the Kubernetes side? Or, is it an abstraction that is codified with documentation, but not by the API?
Kevin: Yeah. And, for the software we control, we make sure we that we reload the components that we know of and that might act oddly. But for the components that we don't control, that might be talking to that API, we might see some weird behavior through this upgrade.
Abe: It's not some atomic timestamp, like Spanner?
Kevin: Nope, because using atomic timestamps means that you have to control for clock synchronization quite tightly. Etcd is designed to not require strict clock synchronization. The wall time always moves forward.
Teleport cybersecurity blog posts and tech news
Every other week we'll send a newsletter with the latest cybersecurity news and Teleport updates.
Future Challenges Around Etcd & K8s Maintenance
Abe: Do you have any notable comments or thing to say to the people who've contributed upstream, who are struggling with the same problems?
Kevin: I think, as a community, we've all gotten into this with this excitement around Kubernetes. A lot of teams and a lot of people have created really great ways to install Kubernetes. Unfortunately, that’s slightly easier than actually running a maintainable system long term. And, I think that's where a lot of companies and a lot of people are running into this issue of now having to define an upgrade story. People use some wonderful scripts to install Kubernetes. Now, they've moved all of their production workloads to orchestrated clusters and now what happens next? How should it be maintained?
Kevin: It'll be exciting to see how different people complete these different upgrade and maintenance stories.
Abe: What's next for you? What’s on the horizon as you come out of the horrors of etcd?
Kevin: Well, right now I'm squashing bugs. I think that the bigger thing I’m going to be looking at is our automation around deploying infrastructure. I’ll be looking to see how we can start an end-to-end deployment of our full platform from higher-level CI/CD systems without having to run “./install”. How to deploy infrastructure beneath the existing automation, how to clean up the varied provisioning methodology to the point where it’s a maintainable baseline the operations teams can work over the long term.
Abe: Wow. So, meta-operations? From a very deep and nuanced focus, you're going to move into broad-scale, the multi-cloud and multi-cluster holy grail?
Kevin: Yeah, and to start using Kubernetes to deploy Kubernetes.
Abe: Oh no. (laughs) Stay tuned for our next horror story!
Kevin: Exactly!
If you’ve made it this far and are interested in working on these types of challenges, please review our open positions or just send us an email: [email protected].
Massive thanks to Taylor Wakefield, Michael Goodness and Steve Sperandeo for providing feedback on drafts of this Q&A!
Table Of Contents
- Introduction
- Who is Kevin and What is Etcd?
- Why Do Consensus Algorithms Matter?
- Why are Autonomous Upgrades of Etcd So Important?
- Finding an Upgrade Path That Allows Downgrades
- Using Full Backups and Restores Beneath Kubernetes
- Dealing with Etcd’s In-Place Upgrade Catch-22
- Using an External Coordinator While Etcd is Down
- Community Projects and How They Handle Etcd Upgrades
- The Horrors of the Backup and Restore Method
- Teleport cybersecurity blog posts and tech news
- Future Challenges Around Etcd & K8s Maintenance
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.
Teleport Newsletter
Stay up-to-date with the newest Teleport releases by subscribing to our monthly updates.